

Miranda: An Open Source Digital Asset Platform for a fast changing world
The Folger Shakespeare Library
ORGANIZATION PROFILE
The Folger Shakespeare Library has the world’s largest Shakespeare collection, the ultimate resource for exploring Shakespeare and his world. The Folger welcomes millions of visitors online and in person, providing unparalleled access to a huge array of resources, from original sources to modern interpretations. The collection covers the whole world of early modern manuscripts, going well beyond works that focus on Shakespeare.
CHALLENGE
An abundance of rich, but very different content
The Folger has over 600 years of human-created content in all forms: written, printed, image, electronic, etc. To view these materials historically a researcher or educator would need to visit the Folger in person. To help share these materials with the world, they needed to share these materials in a way that was readable by people and machines, as well as easily digitally searchable. They wanted to connect their collection not just to the web, but to a growing network of interlinked online collections. The tools they had available weren’t designed for this diversity of types of objects, and the data needed to describe them digitally. While they had some tools to share content online, most were geared towards researchers and experts and the metadata describing the objects was hard to understand. The Folger is widely known in certain academic circles, and they wanted to build on that reputation with a broader audience by helping them find and interact with their collection more easily. They wanted all of their amazing content to be easily and enjoyably accessible to those without PhDs or deep knowledge of early modern manuscript terminology.
Lack of off the shelf marketplace solutions
Like many “mid-sized” institutions, the Folger found that they had outgrown the capabilities of many small scale solutions, but did not have the budget, staff, or need to use the largest enterprise solutions available, and there were no reasonable solutions for smaller or mid-market institutions. The solutions they were using were purpose-built, and only lightly integrated together. This led to collections material being spread out across disparate sites and systems that relied on the end user or researcher to navigate between them. Each system also had its own metadata structure, often leading to uneven or inconsistently described content. Generally, the system was inflexible in storing new types of content, discovering related content, and collecting batches of content together in compelling ways without a large amount of precious staff time. Most of the existing systems were also slow to adopt emerging standards and locked you into managing content into legacy data models.
Current and historic standards didn’t work well for “born digital” content and the juxtaposition of digital and physical materials.
Lack of a flexible system that could easily ingest new kinds of content in addition to historic types meant that adding more content and preserving it for the future was becoming untenable. Proprietary formats, structural limitations on databases, and a lack of a central database all hindered progress. In order to continue to be the leading Shakespeare resource in the world, the Folger needed to be able to translate more of their offline collection online in a sustainable ongoing process that allowed this metadata to be improved, shared, and preserved. They also needed to be able to juxtapose and intersect the growing library of “digital only” artifacts with their robust collection of historic physical artifacts.
“All long projects come with hard moments, but uniformly PTKO has been solution-oriented and thoughtful.” – Gabrielle Linnell, Digital Project Manager, Folger
SOLUTION
 ParsonsTKO embarked on a multi-year project, over two phases. In the first phase, a prototype was created to help explore different technical approaches and encounter and overcome unforeseen challenges while indexing a small fraction of the Folger’s existing digital collection of almost 300K objects. This prototype was iterated on and refined over the course of a year to ensure it was exactly what the Folger needed. The second phase evolved the prototype into a production-ready system that includes the full database of the Folger’s digital assets, called Miranda, and began adding quality of life features.
ParsonsTKO embarked on a multi-year project, over two phases. In the first phase, a prototype was created to help explore different technical approaches and encounter and overcome unforeseen challenges while indexing a small fraction of the Folger’s existing digital collection of almost 300K objects. This prototype was iterated on and refined over the course of a year to ensure it was exactly what the Folger needed. The second phase evolved the prototype into a production-ready system that includes the full database of the Folger’s digital assets, called Miranda, and began adding quality of life features.
Strategy and Engagement
PTKO began by working to understand the current ecosystem, peer community, and industry tools available to The Folger. This included a survey of other institutions attempts to address similar problems, a digital inventory of The Folger’s ecosystem, data, staff capabilities, and tools, and a landscape analysis of technologies that might be useful. It was important to rethink the way The Folger connected people from the outside to their wealth of digital material, the organization itself had to embrace digital scholarship as important.
- Audience research: Combining original source research, peer visits, and expert interviews with a technology landscape analysis of the existing marketplace, PTKO collected this data together and used a blend of quantitative statistical analysis and heuristic qualitative analysis to identify promising directions.
- Iterative Prototyping: PTKO developed the prototype through a series of iterative versions that allowed PTKO and The Folger to incorporate lessons and insights gleaned from real users interacting with the prototype. These iterations helped identify key user behaviors, as well as strategies for dealing with incomplete or inaccurate metadata. The prototype was developed using the same technologies that the production system would leverage: Elasticsearch, JSON Schemas, GraphQL APIs, and the Symfony software framework. The system was designed from the ground up with a modular, component-based architecture, this allows the system to scale up to handle vast amounts of data, and allows customizations to the way data is imported, indexed, and published to be made quickly and easily.
- User Feedback: While the system provided great value simply by collecting all this different data together, the real leap forward for researchers and the public occurred through the iterative improvement of the user interface for the tool. By creating a powerful and digital collection focused search interface, and incorporating feedback from real users, we were able to create a search interface for The Folger that is extremely easy to use, compelling, and allows users of all expertise levels to find useful content within the collection. As part of our modular design, the Miranda client component can be configured with different viewers and data exploring tools that allow Miranda users to use and explore digital content without needing to download special tools or find compatible viewing software.
Technical Architecture/Application and Website Development
The Folger is widely known in certain academic circles, but in order to reach broader audiences, Miranda content needed to be easily and enjoyably accessible to those without PhDs or deep knowledge of early modern terminology. To service this need, and to allow other cultural institutions to easily interact with The Folger’s content, the system was designed to support a sophisticated and modern GraphQL API from the beginning. This API allows both the Miranda Web client, Miranda WordPress plugin, and other systems to directly connect and interact with the Miranda database. This system allows anyone from a high schooler to a huge research library to interface with Miranda easily and enjoyable.
- Flexible Data Modeling: To ensure the asset management system could be sustainable over time, it needed to have a flexible data model that could accommodate new fields being added, some metadata not being available, and yet allowed for strong and reliable record storage. The Miranda data model enforces the integrity of a few core attributes on each record and allows for most other fields and sections to be added and removed to a record over time.
- Strategic Level: The platform provides a purpose-built, audience-focused mobile and web-friendly interface for the search and consumption of assets. The system was designed from the ground up with collaboration in mind, both internally at the Folger, between institutions, and within certain audience groups. This interface is built as “client” to the main system, allowing new versions of it to be built over time, or for a specific purpose. (For example a Miranda on Alexa client) The search index was built using the extremely powerful and scalable Elasticsearch software.
- Modular Design: Allows for low cost and low-risk improvements and modifications to almost any aspect of the system, and offers many opportunities to take advantage of enterprise-grade but commodity priced services and software. The current production system runs on a scalable Amazon Cloud setup.
“The interface is gorgeous, that’s an objective fact! Simple, clean and beautiful, it moves away from clutter and lets individual elements shine. Plus, it’s intuitive to use.” – Gabrielle Linnell, Digital Project Manager, The Folger Shakespeare Library
RESULTS
Engagement and Strategy
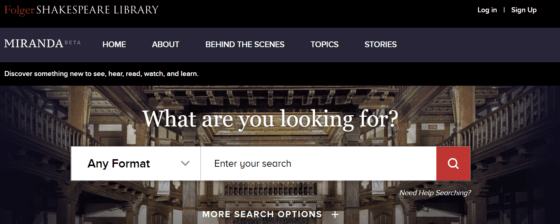
The Folger Digital asset Platform, Miranda, is a clean, elegant site with one search field for all queries. This addresses the variety of users coming to the site (researchers, academics, students, etc.), making it accessible for anyone and everyone to find and view high-quality content and images.
- Find: API first design allows for two directions of traffic—people who visit The Folger and The Folger sending content into the world. This architecture allows developers to pull The Folger library items into their websites or databases with selectable amounts of metadata so that content can be searchable and taggable. An elegant yet simple solution to a problem that creates impact value.
- View: The Miranda client is able to support multiple ways to explore the same content, for images we have both a basic image preview functionality, as well as a sophisticated IIIF Mirador image tool that allows for deep investigation and analysis of high-resolution imagery. These experiences can be easily toggled on and off by visitors.
- Research: Miranda allows users to create their own self-curated collections of content, using a feature called “My Shelf.” This feature takes a skeuomorphic approach, taking the concept of a physical shelf where grad students and researchers could share their resources on a common shelf in the lab and made it virtual. By putting items on My Shelf, a teacher can create a class-specific reading list and share it with her/his students, or that teacher could task their students with creating a shelf as a bibliography for student projects.
Process and Systems Integration
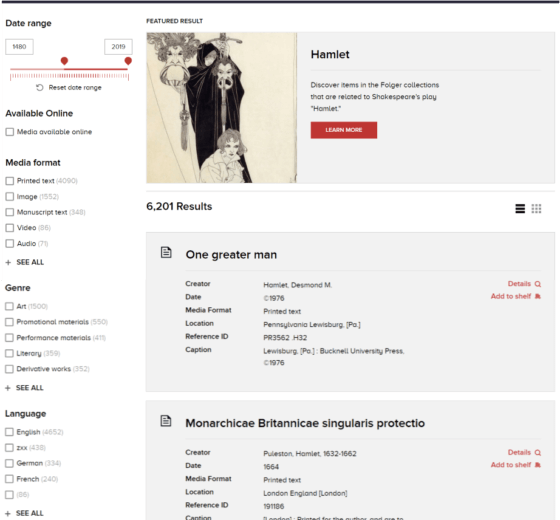
PTKO built foundations for things that weren’t originally asked for, but were seen as important for the future and might be added as funds became available. By planning for future expansion, the system today is ready for enhancement and customization. Miranda is built to scale, and designed to take advantage of cloud architecture. Miranda is also open-sourced, meaning that all future upgrades and improvements will be added to this shared code base, and as The Folger and other institutions improve it, everyone will benefit.
- Share: Graph QL API access is unique in this space but will exponentially help build a growing research community around Miranda. Fast, modern, web applications can be quickly and easily built against this API.
- Search: GraphQL, an open-source query language, was implemented in order to allow sophisticated relationships between content to be exposed via the API. This API is married to a powerful Elasticsearch index that can quickly filter and find useful content in vast databases. This architecture also opens the door for simple upgrades and continuous improvements as the technology evolves, as improvements to Elasticsearch are inherited by Miranda.
- Scale: From a single server prototype, Miranda has evolved into a cloud-native solution, with discrete application containers for key services. This makes Miranda portable, fast, and to deploy.
- Integrity: Data, possibly the most important asset, was given endless thought to best preserve and present (JSON format). The import schema was selected due to compatibility with all use cases, but additional schema can be added for new kinds of assets. The JSON format makes monitoring data integrity and changes to content quite simple and is very compatible with source-control systems such as Git that can add additional layers of change management control if needed.
“Making digital assets merely available is relatively easy. Making them available in an attractive interface is harder, and making them findable through search is harder still. Miranda allows us to leverage the Folger’s digital assets, metadata, and interpretive content to reach the largest possible audience, which helps us achieve our institutional goal of increasing public understanding of Shakespeare and the early modern world.”-Eric Johnson, Director of Digital Access, The Folger Shakespeare Library
Share this case study with a colleague






Explore Miranda
What will you find using The Folger Shakespeare Library’s new database access platform?